
Authored by – Suhas Pachpute
Understanding Iceberg
Apache Iceberg represents a significant leap forward in data storage technology, introducing a high-performance format tailored for huge analytic tables. Unlike traditional storage formats, Iceberg brings the reliability and simplicity of SQL tables to big data while seamlessly integrating with popular data processing engines such as Spark, Trino, Flink, Presto, Hive, and Impala. With Iceberg, organizations can confidently work with the same tables across multiple engines, streamlining data workflows and enhancing collaboration.
Iceberg tables for Snowflake Data Cloud combine the performance and query semantics of regular Snowflake tables with the flexibility of external cloud storage managed by the user. They are ideal for existing data lakes that cannot be or are not intended to be, stored within Snowflake.
The Role of Parquet and Iceberg Catalogs
At the heart of Iceberg lies the Apache Parquet columnar storage format, renowned for its efficiency and compatibility within the Hadoop ecosystem. Parquet ensures optimal data compression and query performance, regardless of the data processing framework or programming language choice.
Moreover, Iceberg introduces the concept of catalogs, enabling compute engines to manage and load Iceberg tables seamlessly. As a leading cloud data platform, Snowflake offers comprehensive support for Iceberg tables through various catalog options. Organizations can leverage Snowflake as the Iceberg catalog or integrate with external catalogs like AWS Glue, ensuring flexibility and interoperability across different environments.
External Volumes: Bridging Snowflake with Cloud Storage
A key feature of Snowflake Iceberg Tables is their ability to utilize external cloud storage for data storage and management. By using external volumes, Snowflake connects seamlessly with storage locations on Amazon S3, Google Cloud Storage, or Azure Storage, allowing organizations to leverage their existing data lakes while harnessing the power of Snowflake’s analytics capabilities.
External volumes act as a conduit between Snowflake and cloud storage, enabling organizations to maintain control over data storage configurations and access controls. This integration eliminates Snowflake storage costs for Iceberg tables while providing the scalability and reliability of cloud storage solutions.
Snowflake Managed vs. Unmanaged Iceberg Tables
Snowflake offers two approaches for managing Iceberg tables: Snowflake Managed and Unmanaged.
- Snowflake Managed Iceberg Tables – In this approach, Snowflake serves as the Iceberg catalog, providing full platform support for managing and querying Iceberg tables. Organizations benefit from seamless integration with the Snowflake ecosystem, including native support for read and write operations. However, organizations must ensure that the external volume used by Snowflake is located in the same region as their Snowflake account to avoid compatibility issues.
- Snowflake Unmanaged Iceberg Tables – For organizations requiring cross-cloud or cross-region capabilities, Snowflake supports Unmanaged Iceberg tables using an external Iceberg catalog. While read operations are possible, organizations cannot convert these tables to use Snowflake as the catalog. External cloud storage accounts may also incur egress costs when querying tables across different regions.
Billing
Snowflake bills your account for virtual warehouse (compute) usage and cloud services when you work with Iceberg tables. Snowflake does not bill your account for the following:
- Iceberg table storage costs: Your cloud storage provider bills you directly for data storage usage.
- Active bytes used by Iceberg tables: While Snowflake does not charge for active bytes, the TABLE_STORAGE_METRICS view displays ACTIVE_BYTES for Iceberg tables to help you track how much storage a table occupies.
Table Types with their Probable Use Cases
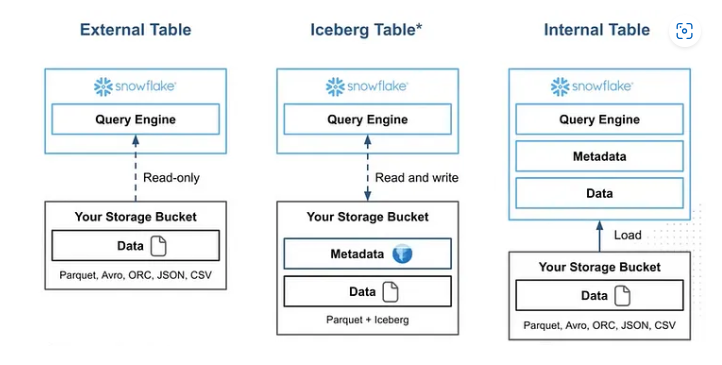
- Native Table – Best for standard use cases
- Snowflake Managed Iceberg – Ideal when data needs to be in an open format, consumable by external processes, and where Snowflake is maintaining the table and catalog.
- Snowflake Unmanaged Iceberg – This is suitable when Snowflake needs to read open-format Iceberg data but acts only as a consumer referencing an external catalog (AWS Glue Data Catalog, for example).
- External Tables – These are used for read-only data hosted in object storage, such as CSV files or Parquet files.
Considerations and Limitations
- Row-level deletes (either position deletes or equality deletes) are currently not possible
- File Format Support is limited to Apache Parquet files.
- The following features and actions are currently not supported on Iceberg tables:
- Iceberg tables don’t support table stages
- Creating a clone from an Iceberg table. Additionally, clones of databases and schemas do not include Iceberg tables.
- Creating temporary or transient Iceberg tables.
- Replicating Iceberg tables, external volumes, or catalog integrations.
- Search optimization service
- Dynamic tables
Conclusion
The different types of tables supported by Snowflake, including Native, Snowflake Managed Iceberg, Snowflake Unmanaged Iceberg, and External Tables, offer versatile use cases catering to various organizational needs.
In summary, Snowflake’s support for Apache Iceberg provides organizations with a powerful, flexible, and efficient data storage solution that enhances data workflows, collaboration, and decision-making, driving innovation and operational efficiency in the modern data landscape.
References
Please refer to the step-by-step guide to create Snowflake Managed Iceberg tables for reference.
https://medium.com/snowflake/guide-to-create-snowflake-managed-iceberg-tables-0a5929761d37





