
Author: Abhinav Singh
Introduction
Snowpark now supports Python. It opens opportunities to bring many workforces to Snowflake to use the highly-scalable computations of Snowflake. In this blog, we will see a use case about how to perform sentiment analysis in Snowpark for Python.
Why Sentiment Analysis?
Sentiment analysis is the process of categorizing opinions expressed in a piece of text, especially to determine if the writer’s attitude toward a particular topic, product, etc, is positive, negative, or neutral.
It is very important to clearly understand what the customers think about your product and service. It helps immensely to manage the brand’s health and brand reputation in the market.
What is Snowpark?
Snowpark provides an API that programmers can use to create Data Frames that are executed seamlessly on Snowflake’s data cloud. Using Snowpark, you can write code in a language of your choice, like Python, and can use the Snowflake ecosystem (virtual warehouses) computation to make operations faster and more secure. In the backend, it translates all the Python code into SQL code and executes it.
Libraries for Sentiment Analysis
There are many open-source libraries available in Python to perform sentiment analysis. Text Blob and Vader are two popular libraries that are widely used in many projects. We are going to see how we can use these two libraries within Snowpark.
Challenges in Using Textblob & Vader with Snowpark
As shown below, Textblob & Vader library is not present in the Snowflake Snowpark ecosystem.
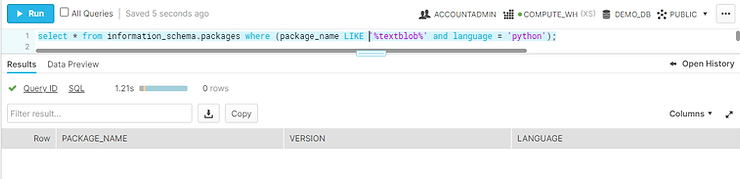
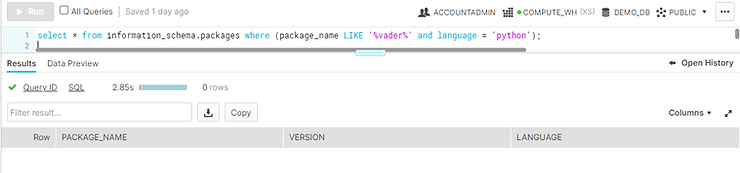
These two libraries are unavailable in Snowflake Snowpark’s anaconda repo. So, we can’t directly import and work on it.
Workaround to Use Textblob & Vader
As a workaround, we can download the .whl file from pypi.org and upload it to the Snowflake staging area. Inside the UDF or SP, we can import the wheel file, extract it, and load it to the Snowpark environment. This will work for us, but we also need to import all the additional dependencies if anything is mentioned in the wheel file.
Steps of Execution
Now let’s see the steps for performing the actual work. First, we will see how we can do sentiment analysis using Textblob.
First, connect to the Snowflake account:
#import libraries
import os
from snowflake.snowpark import Session
#creating dictionary with all the connection parameters
connection_parameters = {
“account”: <snowflake_account>,
“user”: <snowflake_user>,
“password”: <snowflake_password>,
“role”: <snowflake_user_role>,
“warehouse”: <snowflake_warehouse>,
“database”: <snowflake_database>,
“schema”: <snowflake_schema>
}
#create session object passing connection_parameters dictionary
test_session = Session.builder.configs(connection_parameters).create()
- Upload the .whl to the staging area.
test_session.file.put(“textblob.whl”, “@my_stage”, auto_compress=False, overwrite=True)
- Now, let’s create a UDF to find the sentiment of a sentence. We will look into the steps in small pieces.
Next, extract the wheel file and add it to the system path.
import fcntl
import os
import sys
import threading
import zipfile
import nltk
# For synchronizing write access to the /tmp directory
class FileLock:
def __enter__(self):
self._lock = threading.Lock()
self._lock.acquire()
self._fd = open(‘/tmp/lockfile.LOCK’, ‘w+’)
fcntl.lockf(self._fd, fcntl.LOCK_EX)
def __exit__(self, type, value, traceback):
self._fd.close()
self._lock.release()
# Find the import directory location.
IMPORT_DIRECTORY_NAME = “snowflake_import_directory”
import_dir = sys._xoptions[IMPORT_DIRECTORY_NAME]
# set the path to the ZIP file to the location to extract to.
zip_file_path = import_dir + “textblob.whl”
extracted = ‘/tmp/textblob’
try:
# Extract the ZIP File. This is done by using the file lock
# this makes sure that only one worker process unzip the contents.
with FileLock():
if not os.path.isdir(extracted):
with zipfile.ZipFile(zip_file_path, ‘r’) as myzip:
myzip.extractall(extracted)
except:
extracted = path
sys.path.append(extracted)
Now import Textblob and find the polarity score. Depending on the score, find the sentiment of the sentence.
from textblob import TextBlob
score = TextBlob(example_string).sentiment.polarity
sentiment = ”
if score < 0:
sentiment = ‘Negative’
elif score == 0:
sentiment = ‘Neutral’
else:
sentiment = ‘Positive’
The polarity score lies between (-1 to 1), where -1 identifies the most negative and 1 identifies the most positive. Now, let’s see the entire code at once.
create or replace function find_sentiment(example_string string)
returns string
language python
runtime_version = ‘3.8’
imports=(‘@my_stage/textblob.whl’)
packages = (‘snowflake-snowpark-python’, ‘pip’, ‘nltk’)
handler = ‘find_sentiment’
as
$$
def find_sentiment(example_string):
import fcntl
import os
import sys
import threading
import zipfile
import nltk
# For synchronizing write access to the /tmp directory
class FileLock:
def __enter__(self):
self._lock = threading.Lock()
self._lock.acquire()
self._fd = open(‘/tmp/lockfile.LOCK’, ‘w+’)
fcntl.lockf(self._fd, fcntl.LOCK_EX)
def __exit__(self, type, value, traceback):
self._fd.close()
self._lock.release()
# Find the import directory location.
IMPORT_DIRECTORY_NAME = “snowflake_import_directory”
import_dir = sys._xoptions[IMPORT_DIRECTORY_NAME]
# set the path to the ZIP file to the location to extract to.
zip_file_path = import_dir + “textblob.whl”
extracted = ‘/tmp/textblob’
try:
# Extract the ZIP File. This is done by using the file lock
# this makes sure that only one worker processes unzip the contents.
with FileLock():
if not os.path.isdir(extracted):
with zipfile.ZipFile(zip_file_path, ‘r’) as myzip:
myzip.extractall(extracted)
except:
extracted = path
sys.path.append(extracted)
#Find Sentiment
from textblob import TextBlob
score = TextBlob(example_string).sentiment.polarity
sentiment = ”
if score < 0:
sentiment = ‘Negative’
elif score == 0:
sentiment = ‘Neutral’
else:
sentiment = ‘Positive’
return sentiment
$$;
Finally, let’s see if it works with three examples.

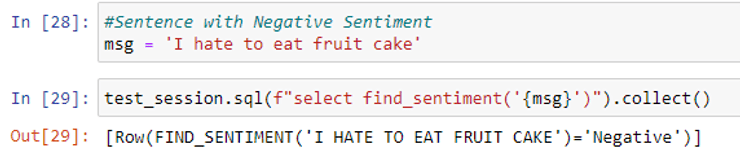
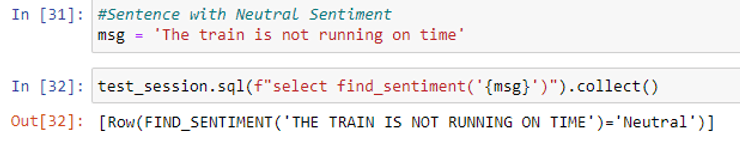
Textblob is very simple to use for beginners to start with sentiment analysis. Still, it has some limitations. In negative polarity detection, when the negation word is added somewhere in between i.e,. not adjacent to the word which has some polarity other than 0, Textblob doesn’t work very well.


TextBlob ‘not best’ differs from ‘not the best and it is an issue.’ In this scenario, the vaderSentiment library will work well and handle negative sentiment very well.
The steps to find sentiment using the Vader library are almost the same except for a few lines of code, which are written below:
#Find Sentiment
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
sid_obj= SentimentIntensityAnalyzer()
score = sid_obj.polarity_scores(example_string)[‘compound’]
sentiment = ”
if score <= -0.05:
sentiment = ‘Negative’
elif score > -0.05 and score< 0.05:
sentiment = ‘Neutral’
else:
sentiment = ‘Positive’
The above lines of code are to find the polarity score and check types of sentiment. For a positive sentiment, the compound score is ≥ 0.05; for negative sentiment, the compound score is ≤ -0.05 and for neutral sentiment, the compound is between]-0.05, 0.05[
Now, let’s see if it overcomes the problem that was there in Textblob with three examples.



As we can see above, vaderSentiment can handle negative sentiment very well.
End Notes
In this blog, we have seen how we can use Textblob and Vader to find the sentiment of a sentence using Snowpark for Python. Vader does better sentiment analysis compared to Textblob when it comes to negative polarity detection. But again, it depends on your use case and your choice of which one you want to use.
References
- https://docs.snowflake.com/en/developer-guide/udf/python/udf-python-creating.html
- https://github.com/cjhutto/vaderSentiment
- https://textblob.readthedocs.io/en/dev/
- https://editor.analyticsvidhya.com/uploads/98719sentimss.png





