Authored by – JP Nellore, Abhijeet Zagade, Vijaykumar Gite
Introduction
One of the biggest hurdles for an enterprise to start a new initiative around data and insights is expediting in GTM by positioning the data to answer the business department’s questions and provide insights.
However, in the current changing dynamics of business, it’s not easy for a program sponsor to get approved for a hefty budget and not provide practical benefits for the business departments.
CXOs typically anticipate comprehensive feedback and measurable outcomes from the program within a quarter’s duration, reviewing progress during Quarterly Business Reviews (QBRs).
Hence, it becomes mandatory for the program sponsor to showcase the progress measured in department onboardings and the value realization of the analytics program.
The actual change in the department’s productivity and efficiency and their general feedback, indirectly reaching the enterprise leadership team, serves as the real testimony to the budget served.
If a program with these fast-paced needs still tries to take a traditional route for modeling data at once and then start the analytics wing of the program, it would neither sustain more than a couple of QBRs nor help the organization at a large scale.
Hence, a need arises for a new data modeling approach that still preserves the benefits of a Data Model as the foundation, provides a Build-as-you-go Data Model, and provides RAD (Rapid Application Development) chunks to the Analytics wing to realize and release to end users.
A well-thought and experimented approach to this modern-day problem is something we coin as “Progressive Data Modeling”.
Progressive Data Modeling expects the data solutions team to work in tandem with different team segments of the program.
Starting with business analysts, data engineers, and data analysts, we will deliver continuous iterations of analytics to end users through horizontal slices of end-to-end pipelines.
A typical Department onboarding plan for my organization Kipi.ai is below.

How does this happen and what does it actually involve?
As mentioned above, Progressive Modeling Starts with Business Analysts talking with Department users to understand their daily activities, pain points, and opportunities for improvement and analytics.
The data engineering team, in collaboration with BAs, then understands the data required for such requirements to be fulfilled and works on bringing that data into the data ecosystem until it is ready to be Modeled. Here is where the magic begins to happen.
Step 1 – Stepping Stone: A Temporary Analytics Layer
The data is quickly modeled by the tag team of BA and DEs, to join the base entities (OLTP) and form a resultset to validate. This layer can be developed in SQL or a Viz tool modeler like Tableau Prep.
A tableau prep model serving workbooks is a smart choice for quick changes and expediting workbook development while adhering to the business requirements through the dashboard. The final model developed in Tableau Prep can be reverse-engineered to form queries for loading the OLAP entities.
If the developer is more comfortable with SQL, the same can be achieved in a temporary layer through the combination of joins and other native SQL clauses.
The BI developer from here can pick up the data, realize it in the dashboard as a prototype, and present the case to end users.
The above process’s iterative feedback and prototyping loop provides quick results to users, and the loop also shapes their vision of expected analytics.
A Data platform like Snowflake Data Cloud fits best in such scenarios, with numerous native features to offer, such as its framework, Unistore, a unified data platform framework for OLTP + OLAP.

Step 2 – A Strong RCC (a common term in Civil Engineering representing a firm foundation Reinforced Cement Concrete)
The second step in this process is to process the knowledge gained from the temp analytics layer and, along with a few enterprise veterans, design the EDW (Enterprise Data Warehouse) level entities.
These entities form a foundation for your data model, like a string RCC of a building.
The frequent data model review calls with Data Engineers, Architects, BAs, and veterans help to design the data model perfectly.
A typical such Model layer architecture looks like the following:
Analytics → Another layer of exposure to downstream focuses on the specifics of the requirement and the sourcing of data from Core Analytics. Can hold second-degree of aggregations
Core Analytics → A layer of exposure to downstream can be at a detail level of entities, joined as required, or aggregated to first-degree
EDW → The bottom layer of the model with strong entities
This step also provides an opportunity for a team to Govern their model and all its related changes in any governing tool or a custom process, thus preserving changes to the model and introducing better control in terms of data security, stewardship, performance, and many other aspects for the best data solution.
Step 3 – A beautiful picture and story to tell
The above 2 steps form a defined, neat model for Analytics to migrate to, thus providing them with a canvas to paint their picture of Analytics and tell the story to gain insights.
The analytics team leverages the benefits of reusability of Core Analytics and Analytics layer views formed of larger entities, thus catering to the needs of multi-attributes of similar granularities that can be rolled up as required.
An Iterative Loop
The above process can be followed in an iterative loop:
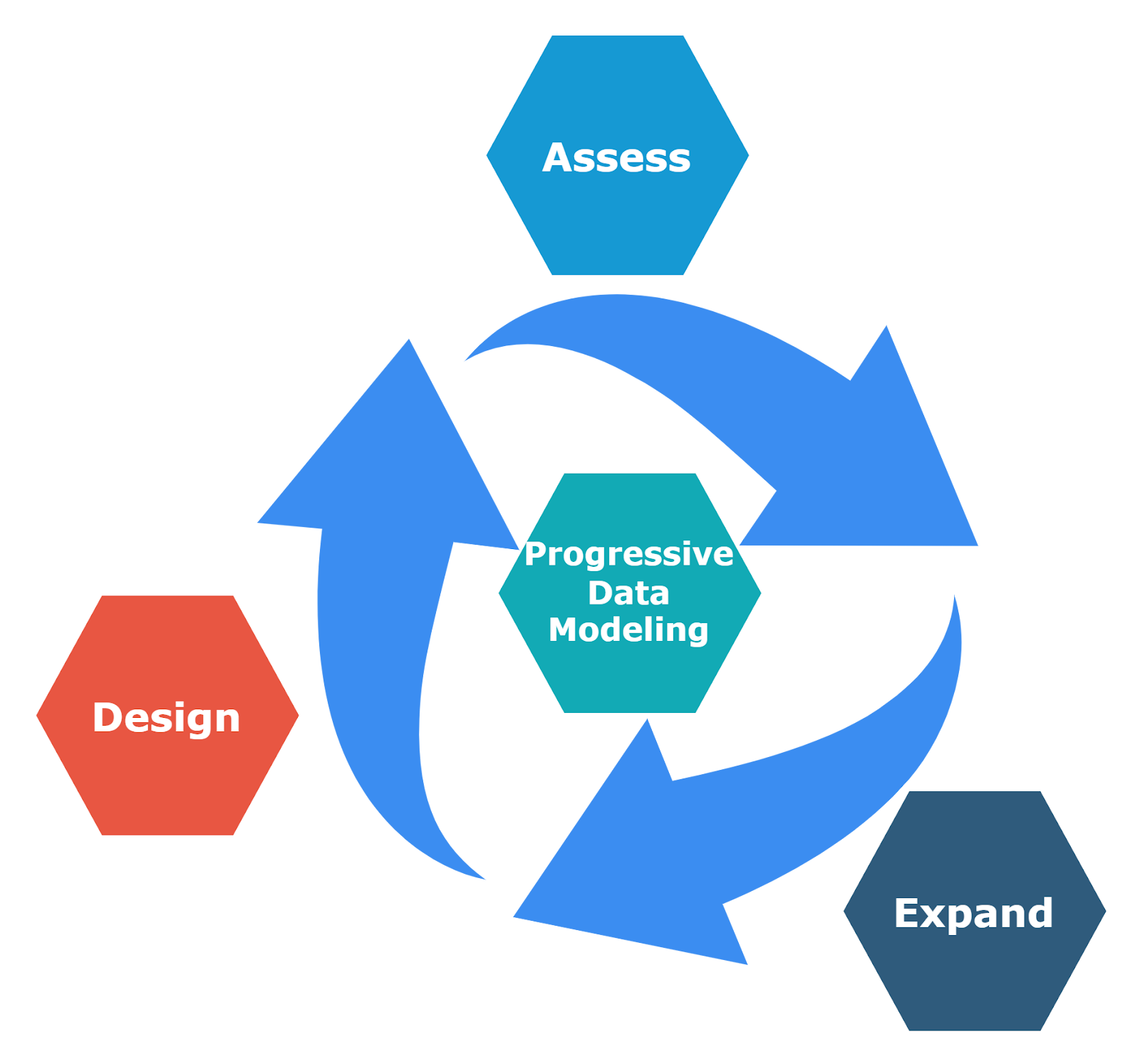
- Assess
For every new requirement, the data team should first assess the requirement to validate if it can be satisfied from the existing objects
- Expand
If the requirement can be greatly satisfied with the base object entity but it is missing a few attributes, such entities can be expanded.
A caution to follow in this step is to validate Horizontal expansion vs Vertical expansion.
Horizontal expansion is the addition of attributes by selecting additional attributes of existing base tables or joining a new base table.
When joining an additional base table, it should be ensured that the existing granularity and record count remain intact and do not result in vertical expansion.
In case of an inevitable vertical expansion, the data model review committee should make a calculated decision, guaranteeing that the change will be absorbed without affecting end reports.
- Design
If the requirement cannot be satisfied with any existing entities or the vertical expansion is beyond absorption, a call can be made to create a new entity and parse it through the Progressive Model process.
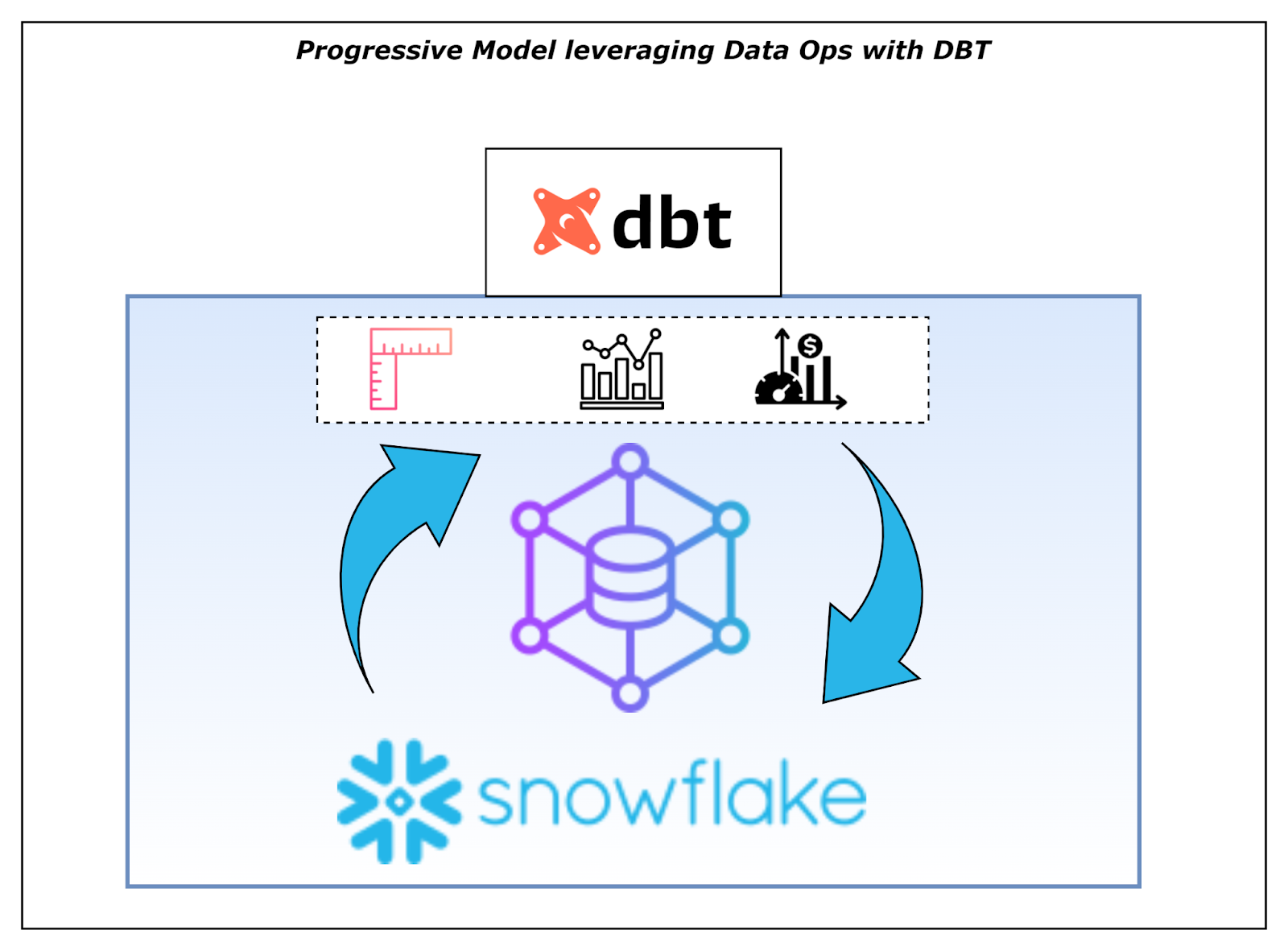
Use of DBT for Metric Layer and Data Model Ops
The above process can be very efficiently implemented using a transformation tool like DBT in the form of a metric layer. Leveraging the GIT integration guarantees a versioned model and increases Deployment speed by following a Data Ops approach.
A powerful combination of tools like DBT and platforms like the Snowflake Data Cloud platform offers a fast GTM data model, thus answering varied business questions with velocity.

Where can a traditional model be a better fit?
With all the merits of a progressive data model we saw in above sections there can still be occasions and scenarios where a traditional Data Model will be more beneficial and apt.
This choice can also be highly influenced by factors such as
- GTM model and urgency
- Time Effort Matrix
- Adaptability of underlying data platform to changes
- Flexible data architecture
One such scenario we can think of is a data model around a product.
A product serving as an application to an enterprise with a defined set of entities and serving as a hybrid OLTP and OLAP model.
There are many such scenarios, so we leave it open. However, it’s worth evaluating the choice based on the mentioned factors.
Conclusion
Progressive Data Modeling emerges as a modern-day solution adept at addressing the complexities of accelerating data-driven initiatives in today’s dynamic business environment. This approach ensures that data models evolve in tandem with business needs by facilitating continuous and iterative development, thereby providing timely and actionable insights. The emphasis on rapid application development (RAD) and horizontal slices of end-to-end pipelines allows organizations to quickly showcase tangible progress and value realization, which is crucial for maintaining executive support and securing budgets.
By integrating Business Analysts, Data Engineers, and Data Analysts, Progressive Data Modeling fosters a collaborative ecosystem that enhances productivity and efficiency across departments.
While Progressive Data Modeling offers significant advantages, it is important to recognize scenarios where traditional data models might be more suitable, particularly for well-defined, stable data environments. Ultimately, the choice of data modeling approach should be informed by the specific needs, urgency, and adaptability of the underlying data infrastructure within the enterprise.
By embracing Progressive Data Modeling, organizations can more effectively navigate the challenges of modern data initiatives, ensuring they remain agile, responsive, and competitive in an ever-evolving marketplace.





