
Author: Honey Pokar
Introduction
Custom classification is a feature in Snowflake, the AI Data Cloud, that allows users to define and apply unique data classification tags based on an organization’s specific data governance needs. This feature is particularly useful for managing sensitive data, as it allows data engineers to create custom classifiers that can identify and categorize data with a high degree of precision. By utilizing custom classifiers, organizations can accelerate their data classification efforts, define industry and domain-specific tags for sensitive data, and have greater control over tracking Personally Identifiable Information (PII) within their systems. Snowflake’s custom classification algorithm uses a scoring rule to evaluate regular expressions that match column value patterns, which helps in recommending the most appropriate tags for data columns. This advanced approach to data classification is instrumental in enhancing data privacy and compliance with regulatory requirements.
What is a Custom Classifier?
In Snowflake, a custom classifier is a class that resides in the SNOWFLAKE.DATA_PRIVACY schema. Once you create an instance of this class, you can invoke a method on the instance to define your semantic category, designate the privacy category, and specify regular expressions to match column value patterns while optionally matching the column name.
Benefits of Custom Classifiers
Custom classifiers offer several benefits for data management and analysis:
- Tailored Data Recognition: They can be trained to recognize specific types of content based on user-defined criteria, making them highly adaptable to unique organizational needs.
- Improved Data Security: By accurately classifying data, they help in the application of appropriate security measures and compliance policies.
- Enhanced Data Management: They facilitate better organization and retrieval of data by categorizing it into meaningful groups.
- Flexibility: Unlike pre-trained classifiers, custom classifiers allow users to define their own categories, providing flexibility and control over data classification.
- Efficiency: They can streamline processes by automating the categorization of data, saving time and resources in manual classification efforts.
- Scalability: Custom classifiers can handle large volumes of data, adapting as new data is introduced and categories evolve.
Step-by-Step Guide
Step 1
Consider the table DATA.TABLES.INVESTMENT, which houses the investment details of clients for an investment firm. The Investment Account Number, unique to each client, serves as an Identifier field and requires appropriate tagging.
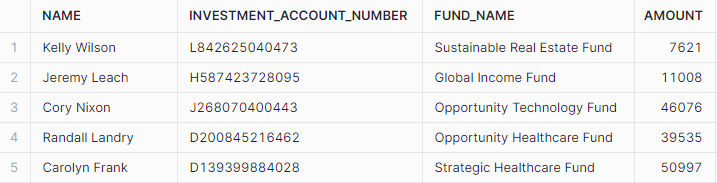
In this context, we employ a custom role, DATA_ENGINEER, having the following privileges:
- OWNERSHIP on table DATA.TABLES.INVESTMENT
- OWNERSHIP on schema DATA.TABLES
- USAGE on database DATA
- USAGE on warehouse COMPUTE_WH
Step 2
The SNOWFLAKE.CLASSIFICATION_ADMIN database role is granted to the DATA_ENGINEER role, enabling the user to create a custom classification instance.
USE ROLE ACCOUNTADMIN;
GRANT DATABASE ROLE SNOWFLAKE.CLASSIFICATION_ADMIN TO ROLE
DATA_ENGINEER;
Step 3
CREATE OR REPLACE SNOWFLAKE.DATA_PRIVACY.CUSTOM_CLASSIFIER
DATA.TABLES.IAN();
The successful creation of the Classifier can be verified using either of the below queries:
SHOW SNOWFLAKE.DATA_PRIVACY.CUSTOM_CLASSIFIER;
SELECT * FROM DATA.INFORMATION_SCHEMA.CLASS_INSTANCES WHERE NAME = ‘IAN’;
Step 4
Subsequently, we add a regex to identify columns containing account numbers using the ADD REGEX method.
CALL ian!ADD_REGEX(
‘Investment Account Numbers’,
‘IDENTIFIER’,
‘[a-zA-Z][0-9]+$’,
‘INVESTMENT.*’,
‘Add a regex to identify Investment Account Numbers in a column’);
Here, each field signifies the following:
- ‘Investment Account Numbers’: Semantic Category
- ‘IDENTIFIER’: Privacy Category
- ‘[a-zA-Z][0-9]+$’: Regex to match the values in a column. In this instance, the regex signifies a string that starts with a letter and is followed by numbers.
- ‘INVESTMENT.*’: Regex for column name
- ‘Add a regex to identify Investment Account Numbers in a column’: Category Description
Step 5
The successful addition of the regex can be verified as follows:
SELECT ian!LIST();
The output should resemble the following:
{
“INVESTMENT ACCOUNT NUMBERS”: {
“col_name_regex”: “INVESTMENT.*”,
“description”: “Add a regex to identify Investment Account Numbers in a column”,
“privacy_category”: “IDENTIFIER”,
“value_regex”: “[a-zA-Z][0-9]+$”
}
}
Step 6
Finally, we classify the data using the SYSTEM$CLASSIFY method:
CALL SYSTEM$CLASSIFY(‘DATA.TABLES.INVESTMENT’, {‘auto_tag’: true,
‘custom_classifiers’:[‘DATA.TABLES.IAN’]});
Each parameter signifies the following:
- ‘DATA.TABLES.INVESTMENT’: Table to be classified
- ‘Auto_tag’: If set to True, it automatically assigns a tag post-classification
- ‘Custom_classifiers’: Allows specification of custom classifiers to be considered.
The classification output is as follows:
{
“classification_result”: {
“AMOUNT”: {
“alternates”: []
},
“FUND_NAME”: {
“alternates”: []
},
“INVESTMENT_ACCOUNT_NUMBER”: {
“alternates”: [],
“recommendation”: {
“classifier_name”: “data.tables.ian”,
“confidence”: “HIGH”,
“coverage”: 1,
“details”: [],
“privacy_category”: “IDENTIFIER”,
“semantic_category”: “INVESTMENT ACCOUNT NUMBERS”
},
“valid_value_ratio”: 1
},
“NAME”: {
“alternates”: [],
“recommendation”: {
“confidence”: “HIGH”,
“coverage”: 1,
“details”: [],
“privacy_category”: “IDENTIFIER”,
“semantic_category”: “NAME”
},
“valid_value_ratio”: 1
}
}
}
As evident, the INVESTMENT_ACCOUNT_NUMBER column is recognized as an IDENTIFIER using the custom classifier.
Step 7
To verify the tag assignments on the column, execute the following query using the ACCOUNTADMIN role:
SELECT *
FROM TABLE(
DATA.INFORMATION_SCHEMA.TAG_REFERENCES_ALL_COLUMNS(
‘data.tables.INVESTMENT’,
‘table’
)
);
For more information on commands used in this post follow the links:
- https://docs.snowflake.com/en/sql-reference/classes/custom_classifier/commands/create-custom-classifier
- https://docs.snowflake.com/en/sql-reference/classes/custom_classifier/methods/add_regex
- https://docs.snowflake.com/en/sql-reference/classes/custom_classifier/methods/list
- https://docs.snowflake.com/en/sql-reference/stored-procedures/system_classify





