
Introduction
Genomics is no longer just a buzzword in healthcare—it’s at the forefront of revolutionizing how we understand and treat diseases. As genomic data continues to evolve and play a pivotal role in precision medicine, the need for seamless interoperability between genomic systems and clinical platforms has never been more critical. For IT developers, this means mastering the complexities of how genetic data flows across different systems, ensuring it’s both accessible and actionable. In this primer, we’ll dive into the essential genomics resources and interoperability standards that are enabling this transformation, and show you how the right frameworks can unlock the full potential of genomic data in modern healthcare.
Background
In recent years, genomics has become a cornerstone of precision medicine, enabling healthcare providers to deliver personalized treatments based on an individual’s genetic makeup. As genomic data grows in complexity and scale, ensuring interoperability—the ability for different systems to communicate and work together—is essential. For IT developers, understanding how genomic data is generated, used, represented and communicated is crucial for supporting initiatives of interoperability and integration with electronic health records (EHR).
Genetic Data Set is Large and Complex
Genomic tests typically involve sequencing DNA and interpreting the results, however, these tests can also be performed on RNA or proteins. These tests are conducted on different types of human samples or repeated on one type of sample over time. There are several different types of tests, each of which can be performed using different sequencing technologies. In some instances, the results of one sequencing test is further validated through additional sequencing tests. In other instances, the samples of proband (patient) and the parents are sequenced for inheritable diseases or that of donor and recipient are sequenced to determine histocompatibility for organ transplant. Diagnosing and monitoring diseases using NGS has become a widespread practice. In a previous article, we described the various data formats to save the results from NGS experiments and how to make ‘sense’ of the results. The sequence data stored in the FASTQ, SAM/BAM and VCF format constitute the patient’s primary data. The primary data can be interpreted only by genetic medicine specialists who summarize the diagnostic interpretations and care considerations for use by physicians.
The results typically involve identification of aberrations (called variants) of the patient’s sequence at specific (known) sites when compared to that of a reference sequence (typically). The size of the summary file that contains the structured keywords, diagnostic interpretations and patient care consideration is in the order of kilobytes; this result is extracted from primary data that is up to multiple hundreds of gigabytes in size. This ‘compression’ of the genetic data allows the genetic medicine specialist to communicate clinically relevant insights.
The primary data (FASTQ and SAM/BAM files) and summary results generated at the sequencing labs are then shared with the provider organization. The primary data are stored in document management systems, and the PDF file received is uploaded into the EHR system for review by physicians.
FHIR Genomics Resources
Realizing the widespread implications of genomics that takes into account individual variability in genes, environment, and lifestyle for each person in healthcare, Health Level 7 (HL7), the international organization that develops standards for healthcare data exchange using Fast Healthcare Interoperability Resources (FHIR) standards stepped in to normalize the communication of genomics information across systems and organizations. FHIR is composed of various linkable and extendable data structure specifications known as resources, which represent concepts in healthcare scenarios, such as patients, conditions, and clinical observations and reports. These resources in the JSON, XML or Turtle/RDF format can be customized for specific use cases through standardized constraints and extensions, referred to as profiles. Teams at HL7 developed resources for standardized representation of Genomics data.
Empower Genomic Data Integration with kipi.ai’s FHIR Integration Native Apps
Ready to transform how genomic data integrates with clinical systems? Discover how Kipi.ai’s FHIR Integration Native Apps, available on Snowflake Marketplace, simplify the process of managing and exchanging genomic data. Unlock seamless interoperability and support precision medicine initiatives with solutions designed for developers and healthcare organizations. Explore our FHIR-native tools today and take the next step in advancing healthcare innovation.
As can be gleaned from the discussion above, Genomics data originates from the DNA sequencing equipment and passes through a bioinformatics pipeline to become clinically relevant. Meanwhile, clinical data is obtained from everyday healthcare operations – electronic healthcare records, lab systems, and clinical platforms.
The Genomics Reporting implementation guide focuses on ways to merge genomics data with the clinical reporting workflows in healthcare systems for everyday healthcare operations, including clinical sequencing, cancer screening, pharmacogenomics, public health reporting, and decision support tools. This involved updates to the profiles on the existing resources—Observation, DiagnosticReport, ServiceRequest, Task, and FamilyMemberHistory—to support the sharing of genetic test results, including observed variants from reference sequences and their clinical implications and interpretations. The following image represents a high-level construct of the Genomics Report.
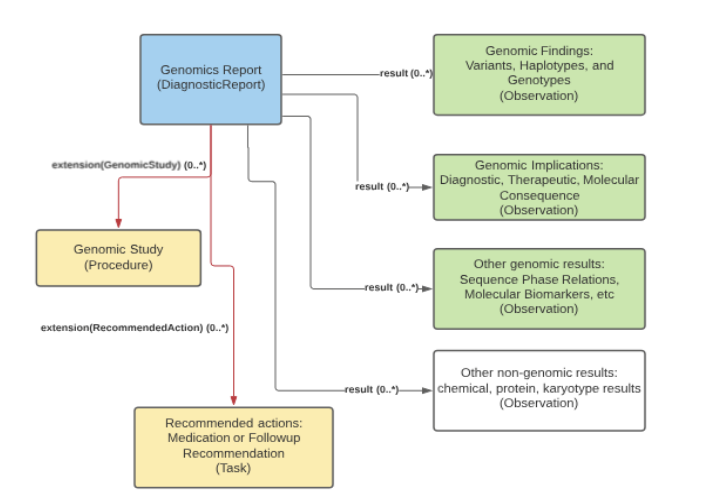
The focus of Genomics Reporting Implementation guide is to share the outcomes from the bioinformatics pipelines, however, to realize the full potential of genomics data, access to more granular data is required. This led to the introduction of two new FHIR base resources—MolecularSequence and GenomicsStudy.
The MolecularSequence resource stores detailed raw genomic sequence data (e.g., DNA, RNA, protein sequences) and associated information; alternately, this resource will contain information about the endpoints from where the sequence can be obtained. Note however, that information like variant, variant annotations, genotypes, haplotypes, etc., are presented via the Observation resource.
The GenomicStudy Resource specifies information relevant to the genomic study, which includes one or more analyses, each serving a specific purpose. These analyses can vary in different ways based on the method, device used, the region targeted, the performer of the test, the region targets, or the bioinformatics software used for the analysis. While results are stored as Observations within DiagnosticReports, both can reference back to their source GenomicStudy, unlike the Genomics Report profile.
Together, these two base FHIR resources allow for efficient management and exchange of fine-grained genomics data, supporting both clinical operations as well as research / public health needs.
Opportunities for Growth in Genomics Resources
While HL7 FHIR Genomics resources have made significant strides in improving the exchange and management of genomic data, there is still much work to be done. As next-generation sequencing (NGS) technology evolves, it can identify thousands to millions of genetic variants. The FHIR Genomics Reports only capture a subset of these variants, and continual updates are necessary to stay on top of the latest interpretive information. The introduction of new resources like MolecularSequence and GenomicStudy has made it possible to access more granular data, but the full potential of genomic data can only be realized by refining the tools that enable its analysis and integration.
Conclusion
The importance of genomic data in healthcare continues to grow, and ensuring the effective management and exchange of this data is essential. By leveraging Kipi.ai’s FHIR resources, developers can seamlessly integrate genomic information into clinical workflows, supporting precision medicine and improving patient outcomes. However, as the field evolves, ongoing innovation and development in genomic resources are necessary to fully harness the power of genomics in healthcare
About kipi.ai
Kipi.ai is a leading analytics and AI services provider, specializing in transforming data into actionable insights through advanced analytics, AI, and machine learning. As an Elite Snowflake Partner, we are committed to helping organizations optimize their data strategies, migrate to the cloud, and unlock the full potential of their data. Our deep expertise in the Snowflake AI Data Cloud enables us to drive seamless data migration, enhanced data governance, and scalable analytics solutions tailored to your business needs. At kipi.ai, we empower clients across industries to accelerate their data-driven transformation and achieve unprecedented business outcomes





