
Challenge
Snowflake’s 16MB size limit on the variant data type creates challenges in managing and processing large JSON objects. This constraint impacts JSON data storage, retrieval, and maintenance within the system
Kipi’s Solution
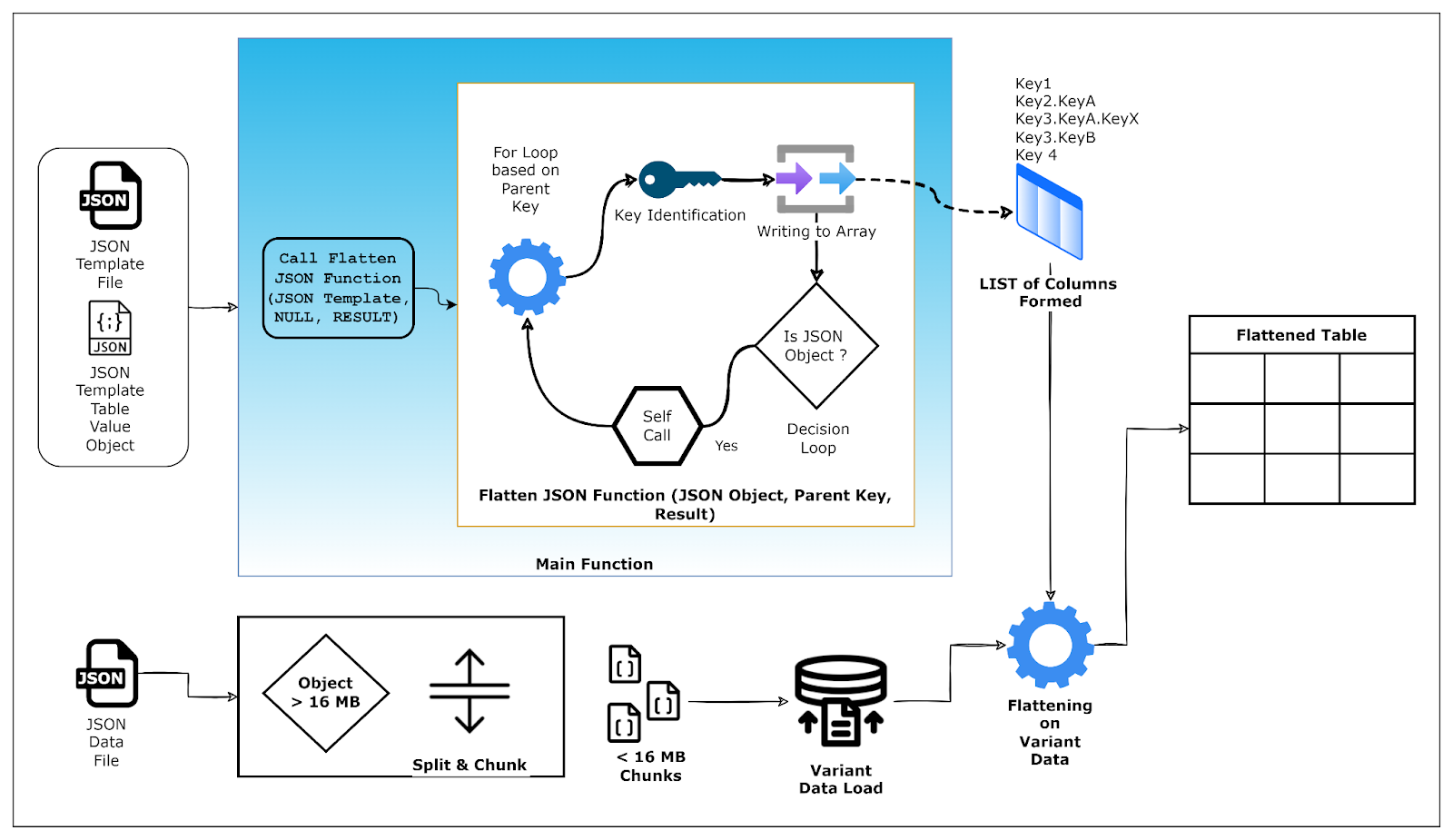
To address the 16MB variant column size limitation in Snowflake, we have come up with a comprehensive solution all incorporated and computed in Snowflake:
- Handle large JSON object files (>16MB) by chunking them into multiple parts and loading each chunk into the Snowflake variant table.
- Integrate the large JSON chunks with the flattened statement to produce a structured table.
- Each JSON object is assigned a unique identifier to link its chunks together. The data is then condensed by grouping on this identifier, resulting in a cleaner table with one filled record per ID. This process is managed by Snowpark Python, a powerful native runtime framework in Snowflake Cloud Data Platform.
This approach ensures that despite chunking, which may introduce NULLs in some rows, the final result is a well-organized and complete record for each JSON object.
Below is detailed breakdown of each stage:
Pre-Process
The intelligent Snowpark stored procedure splits a large JSON file into <= 16MB chunks and uploads them to an AWS S3 bucket. The procedure uses the boto3 library to interact with S3 and the snowflake.snow park library to handle Snowflake sessions. It calculates the number of chunks required based on the file size and chunk size, then iterates through the file to read and split it accordingly. Each chunk is assigned a unique Parent_Identifier, which helps to track and reassemble the chunks if needed. The final structured data, including the identifier, is uploaded to the specified S3 bucket.
Process
The intelligent JSON dynamic flattener core process , parses the chunk loaded to table as an individual row , and creates a flattened query with all available column names identified.
Post Process
The later part of the flattener process, using the SQL generated , flattens the data in a structured table (created on the fly) and loads data with row to row mapping.
The latest part of the process then identifies the Chunk Identifier to understand the relationship between multiple rows, and all rows belonging to the same ID, get condensed into a single row with NULLs compressed for individual columns.
For example →
Non Condensed flattened data
| Chunk_ID | Col1 | Col2 | Col3 | Col4 |
| 99991 | horse | |||
| 99991 | cart | |||
| 99992 | blue | |||
| 99992 | wagon |
Condensed Data
| Chunk_ID | Col1 | Col2 | Col3 | Col4 |
|---|---|---|---|---|
| 99991 | horse | cart | ||
| 99992 | blue | wagon | ||
Limitation to solution
A fair limitation to this solution still remains a multi- nested JSON , which becomes practically very complex to split and parse to individual JSON objects in the first place.
Outcome
Most of the complex bundle FHIR files and Pricing Transparency JSON files , have JSON objects but have numerous properties making them individually 16 MB+. This solution seamlessly handles such files and converts them into a structured native table form to be positioned and realized in analytics.





