Implementing A Centralized Data Lake and Data Warehouse for Germania
Introduction
Germania is a 125 years old insurance company based out of Texas providing auto, home, farm, rural, property, business, umbrella liability, church, RV, tenant-occupied, condo & townhouse, and renters insurance. Kipi.ai being an expert in Snowflake and the insurance domain is helping Germania in becoming more Data Driven by leveraging modern analytics through Snowflake.
The Opportunity of Optimizing Cost
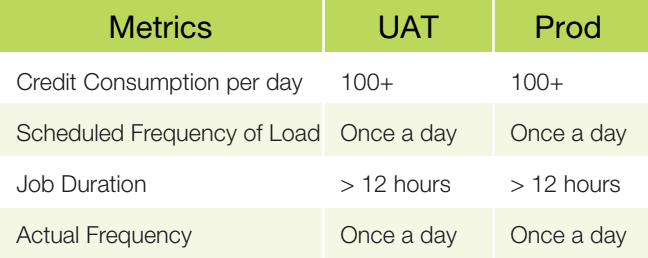
The Legacy state saw a consumption of over 100 credits per day for both UAT and Prod environments, with a scheduled frequency of once a day for UAT and twice a day for Prod. However, the actual frequency was only once a day, with jo durations exceeding 12 hours.
Root Cause Analysis
A root cause analysis was conducted, which identified several issues contributing to the high costs and long job durations. These included:
Issues
- Larger Size Warehouse for both UAT and Prod
Environments - High Cloud Services Cost
- Most Time consumed in Copy Into for CDA
Load - Complex Regex file listing
- No archival of files
- Sequential Process
- Over 1 million files per day, with an average
size of 4 KB
Cost Optimization Measures
To resolve these issues, the team implemented an iterative progress plan, which included analyzing, actioning, and analyzing the model again. Several solutions were implemented, including:
1. Rightsize Warehouse Size
The team identified that the size of the warehouse was larger than necessary, which was contributing to high cloud services costs. To reduce costs, the team implemented a process to reduce the size of the warehouse by removing unnecessary data and optimizing the storage of relevant data.
2. Increase Max Thread Concurrency
To reduce the job duration of the project, the team increased the maximum thread concurrency, allowing more threads to be processed simultaneously. This improved the speed of the data processing and reduced the overall job duration.
3. Segregation Warehouse
The team implemented a solution to segregate the warehouse for UAT and Prod environments, which allowed for more efficient processing and reduced the overall cost of the project.
4. Enable File Retention Policy
To prevent a buildup of unnecessary files, the team implemented a file retention policy, which automatically deleted files that were no longer needed. This helped to reduce the overall size of the warehouse and improve performance.
5. Merge Files For Optimal Sizing
As part of ongoing work, the team is currently implementing a solution to merge files into optimal sizes. This will reduce the number of files that need to be processed, improve the efficiency of the data processing, and further reduce the overall cost of the project.
6. Offload Snowflake From Listing of Files
Another ongoing work solution is to offload Snowflake from the listing of files. This will reduce the time taken to list files and further improve the performance of the project.
7. Enable Asynchronous Processing
The team implemented a solution to enable asynchronous processing, which allowed for faster and more efficient processing of data. This helped to reduce the overall job duration and improve the performance of the project. By implementing these solutions, the team was able to optimize the cost and performance of the Germania Data Lake project, resulting in a significant reduction in credit consumption and cost savings for the organization.
Results
Post-Optimization State
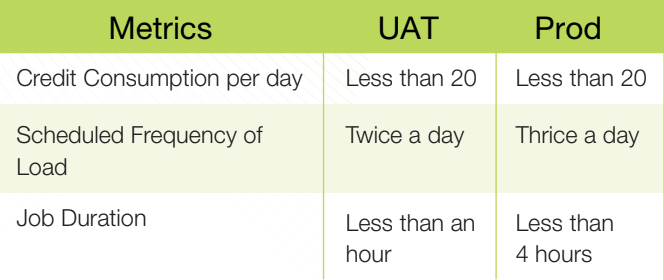
As a result of these solutions, the Improved state of the project has seen a significant reduction in credit consumption, with less than 40 credits consumed per day for both UAT and Prod environments. The scheduled frequency of load for Prod is twice a day, while UAT has been increased to 12 times a day. Job durations have also been significantly reduced, with Prod taking less than 4 hours and UAT taking less than an hour.

Conclusion
Overall, Germania was able to save substantial costs from these optimizations, which resulted in a considerable decrease in daily credits from more than 100 to only 60. The job duration was also brought down to one and four hours on UAT and Production, respectively. As a data professional moving slowly is rarely an option, and there is no compromising on data quality – bad data is too expensive no matter the price.
About kipi.ai
kipi.ai helps businesses overcome data gaps and deliver rapid insights at scale.
With Snowflake at our core, we believe good data has the power to enable innovation without limits, helping you say goodbye to complex data solutions and hello to the modern world of cloud elasticity.
Kipi earned Snowflake’s Americas System Integrator Growth Partner of the Year Award at the 2023 Snowflake Summit and holds 7 industry competency badges.
Kipi is committed to pioneering world-class data solutions for Snowflake customers including 50+ Accelerators, Enablers, Solutions, and Native Apps to boost performance within Snowflake.
Let kipi.ai become your trusted partner for data and analytics and we’ll empower your teams to access data-driven insights and unlock new revenue streams at scale.



