Author: Sudhendu Pandey
Introduction
The primary function of IT is to serve as the technical arm of the business and maximize its computing power & technical efficiency. That has been a focal point since the advent of software and always will be. What really changes is the dynamic of how to serve (and who is serving, and what is served, etc..). Tracking the lineage of any technology is much easier if we know what is being produced, what is consumed who is producing and who is consuming. Everything in between is where the magic lies.

Interesting Ideas in Technologies

Firstly, I believe that every field of IT is seeing some very interesting growth.
Depending on where your focus is, the technology landscape is evolving everywhere. In my decade of working in IT across the vast yet narrow spectrum of technologies (TIBCO, Dell Boomi, Integration, Warehousing, Cloud, Analytics, Data Science, and now Data) I have come to realize, irrespective of where you are, there is a fractal growth of interesting ideas within it. You just have to look for it. Modern Data Stack is one such fractal growth evolving within the data stack!
Modern Data Stack: Encounter

Although Snowflake genesis is data warehousing and undoubtedly that is where the stronghold is, Snowflake is already diversifying horizontally to ensure they serve the entire end-to-end data flow. Snowflake is no more a data warehouse company, it is a Data Cloud company.

Modern Data Stack: Understanding the Context

The modern data stack is the ‘cloud’ answer to the legacy data stack. In fact, the phrase Modern Data Stack is in line with the ‘tech stack’ term that is quite common in the industry. It is surprising how recent is this term (some guess says 2020).
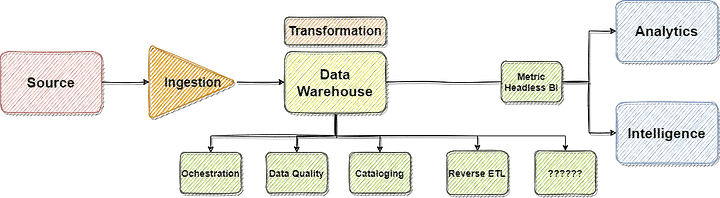
To understand the use of each component of Modern Data Stack, let us start from our ‘source to target’ journey. From there, we will understand the different stages.
In data analysis, usually, the target is analytics (and intelligence tools)
Stage 1
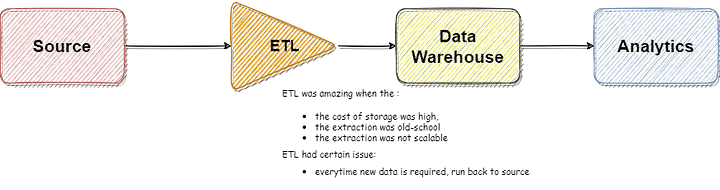
At first, it was ETL. This was the de facto standard until quite recently (pre-data lake and Cloud data warehouse era). The important point to note is Transformation is done before loading the data. Used to work like charm but is not the first preference nowadays for any data pipeline requirement.
Stage 2
With the rise of cheap cloud storage (AWS S3, Azure Blob Storage, Redshift, Google Bigquery, etc), it is now more sensible to extract everything, load it in the data warehouse, and then do the Transformation over it.
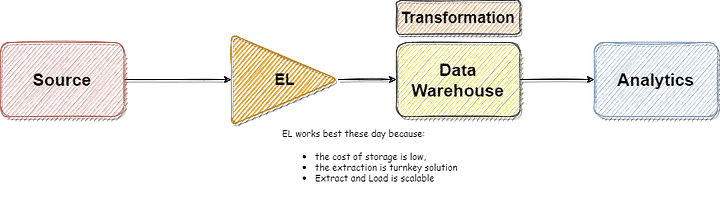
Few benefits of doing this:
- Decoupling the Extract Load (EL) from Transformation (T). This means certain tools and technologies can get the EL going while others can do transformational logic. This also enables transformation within the data warehouse, which means the data never goes out of the warehouse. This looks like a simple switch of alphabets, but it’s a massive step forward.
- The precursor to Self-service Reporting. You want your analytics team to have all the data in one place so that they can do their job instead of following up with the EL team to get data every time a new requirement comes in. With EL first, the reporting team has everything in one place to get going.
Stage 3
With the T away from the EL, one of the main challenges now is how do you ensure things run in proper sequence, in other words: how do we ensure proper orchestration? Imagine you are loading data from 10 sources and you want to create an aggregated table once all the data from all the 10 sources are loaded. When and how do you schedule your transformation? Too soon and you will have incomplete data, too late and you will have time wasted. This is where the next component of Modern Data Stack comes in, the orchestration layer. The orchestration layer here is exactly what a middleware did to EAI, it helps these tools talk to each other and manage dependencies. So your orchestration tool logic can say, fine; once I have done the extraction of data from these 4 sources, I will then schedule my transformation, and then extract data from the 5th source, and then do the final transformation post which I will validate the data. So on and so forth.
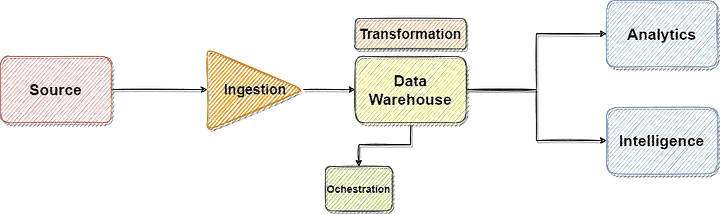
Stage 4
Since now we have different tools doing the different tasks (Ingestion, Transformation, Orchestration), there has to be a place for data quality check. In the olden days, the tools such as Informatica, Mulesoft, Dell Boomi, TIBCO* did everything in itself. You could write assertions, unit test cases, test packages, etc within the tool.
In our Modern Data Stack, we thus need a component to help us check the data quality (QA).
* I know some of these are not ETL tools, but they can be used as one.
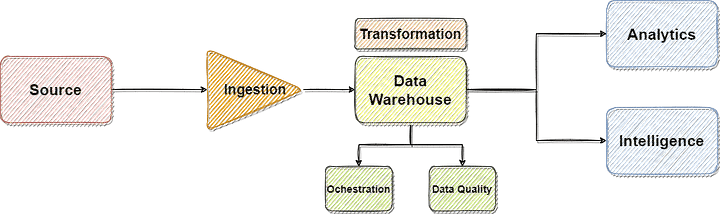
Stage 5 and beyond….
If you get a bit of hint here, you will see a pattern, the Modern Data Stack breaks down the gigantic ETL tool functionality into discreet tools. This not only gives users the choice of selecting one tool for Ingestion vs different for Transformation, but it also prevents vendor lock-in.
We can now keep adding more components to the above diagram. There is no definite list of components you can add to a modern data stack (since it is in infancy and evolving every day). But to summarize, below are the most prominent ones.
Cataloging: Where is the data coming from? Which system is the data column ‘reservation_id’ sourced from? Data Cataloging tools help bring governance, trust, and context to data. Read more here.
Reverse ETL: What if we could feedback our analysis from our data warehouse back to the source systems? There seems to be a growing need to reverse ETL, which basically means once we have insight from the data, push it back to the source to ‘inform’ the source. More detail here.
Meric Layer: As of now, metrics are embedded into the BI layer (thing of all your metric logic in Tableau or Looker). In his classical article, Benn writes, without a single source of metric layer, metric formulas are scattered across tools, buried in hidden dashboards, and recreated, rewritten, and reused with no oversight or guidance.